Create small sets of avatars (number of avatars < 1000) takes a short time and can be done in a synchronous way (the client waits for the end of the creation), but when this task implies several thousands of avatars, the creation time is too high and then the client can not wait for hours and the connections could end due a time out.
To scope with this issue, Thing in provides a dedicated mechanism named "batch process of avatar creation".
It could be used through the API endpoint /batch/process.
A process takes mainly a file that contains the avatars to create in RDF/Turtle format. This file should be transmited to Thing in thanks to a url (starting with http:// or https://) or as a Blob (the format should be blob://<blob_uuid>). The content could be gziped (a the creation of the process, the specification of this encoding must be indicated).
Upon a process is created, it is not run, it is in a STOPPED status. To execute the process a command RESUME should be sent to it. When the process enter in a RUNNING status, it is put in a queue waiting for a free runner to take it in charge (the setup of this process is set to QUEUED). When the process is effectively running on a runner, this runner put in place the needed context.
- It downloads the file, if it is not already downloaded (setup =
DOWNLOADING). As the size of the file is given by the remote storage (fileSize), the download can be followed with thedownloadedSize. - It unzips the file, if the file is encoded with gzip (setup =
UNZIPPING) - Then if all it's done, put setup =
READY, otherwise set the setup =FAILEDand abort the process
When the setup is ready, the core process could be executed.
- (step
INIT) Initialize a local structure that allows pause resume of the creation. This structure is persisted on the runner storage, it can be considered as a fast database for this process. At the end of this step, the total number of avatars (avatarNumber) and total number of relationships (relationshipNumber) is known and can be used to follow the progress of the creation. - (step
CREATING_AVATARS) The avatars and their data properties are sequentially created by chunk. This creation can be tracked with thecreatedAvatarNumberparamter. - (step
CREATING_RELATIONSHIPS) The relationshipd are sequentially created by chunk. This creation can be tracked with thecreatedRelationshipNumberparamter. - (step
CLEANING) When all avatars and relation are created, all the working file are deleted (downloaded file, unzipped file, local database) - (step
SUCCEED) done.
If at any step, the process fails, it goes to step FAILED.
If a process is in setup FAILED or step FAILED, it can not be resumed.
The user that has created the process, has the responsibity to kill it by sending a command KILL. A kill can be only applied on a STOPPED process and it removes all the reference of this process.
In the following, we give the state transition schema:
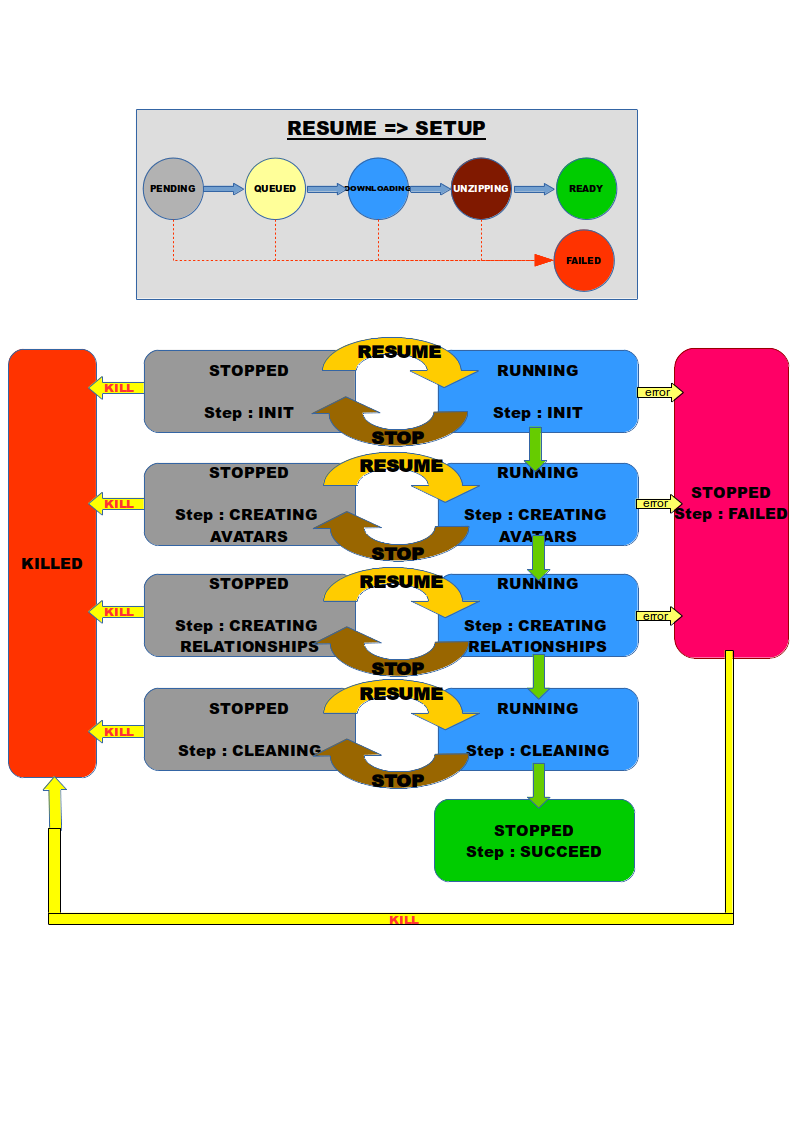
¶ process minimal example
Follow the steps below to upload savec in a file. The file may be available as :
- an url
- a blob
files saved on the local filesystem are not yet supported (tbd). You can use the blob method below instead.
- (Optional) : first upload a blob with your avatar files (if the file is available with an url, you can skip this step.
Payload example :
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://www.example.com/ex/test7> rdf:type <http://purl.oclc.org/NET/ssnx/ssn#Device> .
The payload must be in turtle syntax (this format was preferred as it is easily streamable for large files).
Post this file to /blobs/ (file parameter). GZipping the file is possible but not mandatory.
This will return the blob uuid to use in the next step :
{
"uuid": "{uuid}"
}
- Post to /batch/process the following minimal payload :
When using an url :
{
"ignoreDuplicateOnCreation": true,
"url": "{yourUrl}",
"description": "my batch process from a url",
"defaultVisibility": 0
}
When using a blob :
{
"ignoreDuplicateOnCreation": true,
"url": "blob://{yourBlobUuid}",
"description": "my batch process from a blob",
"defaultVisibility": 0
}
If the file was gzipped, add the following to the payload :
"contentEncoding":"gzip"
This will return your process status along with its id to use in the next step:
{
"id": "{myProcessId}",
"description": "test avatar",
"requesterId": "cf29c17e-33b8-4c82-969f-096d09cc2251",
"domains": [
"http://",
"https://"
],
"ignoreDuplicateOnCreation": true,
"url": "blob://5d631f72-b5c4-4061-914f-66eed589fb50",
"targetDomain": "",
"contentEncoding": "",
"defaultVisibility": 0,
"status": "STOPPED",
"setup": "PENDING",
"step": "INIT",
"runner": "d35dc1a39066",
"registerTime": 1666602058591,
"resumeTime": 0,
"stopTime": 1666602058591,
"lifeTime": 1666602058591,
"fileSize": 152,
"downloadedSize": 0,
"unzippedFileSize": 0,
"avatarNumber": 0,
"relationshipNumber": 0,
"createdAvatarNumber": 0,
"createdRelationshipNumber": 0,
"log": [],
"srcUuid": "1f2f221b-790d-4fc7-a9cf-0fafcc5bb042"
}
- post to /batch/process/{myProcessId}
Set the “command” parameter to “RESUME”
¶ domain
In the process a domain can be specified in the targetDomain attribute. But this domain is used as baseUri for injected turtle file, so that if the uris of avatars in turtle file are absolute, the domain will be ignored
If we inject the following ttl file
@prefix mypoles: <poles/> .
mypoles:Orange
a <http://schema.org/Corporation> .
If we specify a domain http://myexample.com/ the created avatar will have the following iri: http://myexample.com/poles/Orange
Now if the prefix is
@prefix mypoles: <> .
the created avatar will have the following iri: http://myexample.com/Orange
But if the prefix is
@prefix mypoles: <http://fullUri/> .
the domain will be ignored and the created avatar will have the follwing iri: http://fullUri/Orange